很久了,没写过什么的东西,这两天看了些记录,然后想起这个事情,就写写吧。
我是一个比较关心网络交互的人,自己做的网页,多多少少都会插入一些统计的插件,用来分析流量,观察我们的来访者。
当你打开浏览器,访问一个网站(网址)的时候,你到底提交了什么信息呢?浅显的,对于到多数同学都了解,你告诉了网站你访问(请求)的网址,实际上,还有很多数据呢。
首先,对于服务器,它需要了解你访问的是什么域。你进行网络访问的时候,通常不是通过 IP 地址找到服务器的,你首先输入的地址里面,包含的域名,比如 www.google.com,www.renren.com之类的,你访问的这些地址,只是为了方便人类去记忆,浏览器首先会通过 DNS 将这些地址翻译成为我们计算机网络能够进行通信的 IP 地址,例如 Google 的网址,可能是:74.125.71.105。对于服务器,IP 地址就是他家的门牌号,你因为一个www.google.com的地址找到某一个门牌好,它也需要了解你到底为了那个请求而来,因为在我们的互联网上,域名和 IP 地址的关系是多对多的,可能是一个 IP 地址被绑定了多个域名,也可以一个域名对应了多个 IP。一般这部分,是通过服务器的 Web 容器(我喜欢把 IIS,Apache 之类的称之为 Web 容器)完成的。前者为的是尽可能多地利用 IP 地址资源,因为有一些站点访问量并不是特别多,如果这样的小站点也要占一个 IP,或者说占用一个服务器,显然有些浪费;后者呢,对于一些大的站点,一台服务器是抵档不住世界各地的访问量的,所以,我们需要将访问量平摊到镜像服务器上面,有些情况下,为了让用户获得更好更快的服务器,DNS 有时候也会有区域解析,使用户可以访问就近的镜像服务器,或者是绕行 CDN 网络。
服务搞清楚你为什么而来之后,然后,就需要你请求的页面。比如你没有提交什么访问的子页面,光溜溜地要访问 http://www.google.com 这种类型的 URL,那么,服务器会找出对应的默认文档提交给你,一般服务器设置的时候,有如下这样的一些:index.html、index.php、default.html 之类的。
服务处理完对应的请求,就会把内容发送给你,这里,服务器在你来的时候,就已经把你的 IP 地址记录下来了,然后,它会根据对应的 IP 地址把内容发给你。当然,因为 HTTP 是 TCP 协议的,服务器不知道你的地址,自然没办法跟你通信。
上面的这些,是基本的 Web 信息请求,相信有过基本浏览网页的童鞋都会清楚,其实,还有很你们平时并没有注意的内容被传输了。
我们来看一张访问 Google.com.hk 的截图,这个是 Chrome 里面的开发人员工具,对于大多数 Webkit 内核的浏览器都有这个功能:
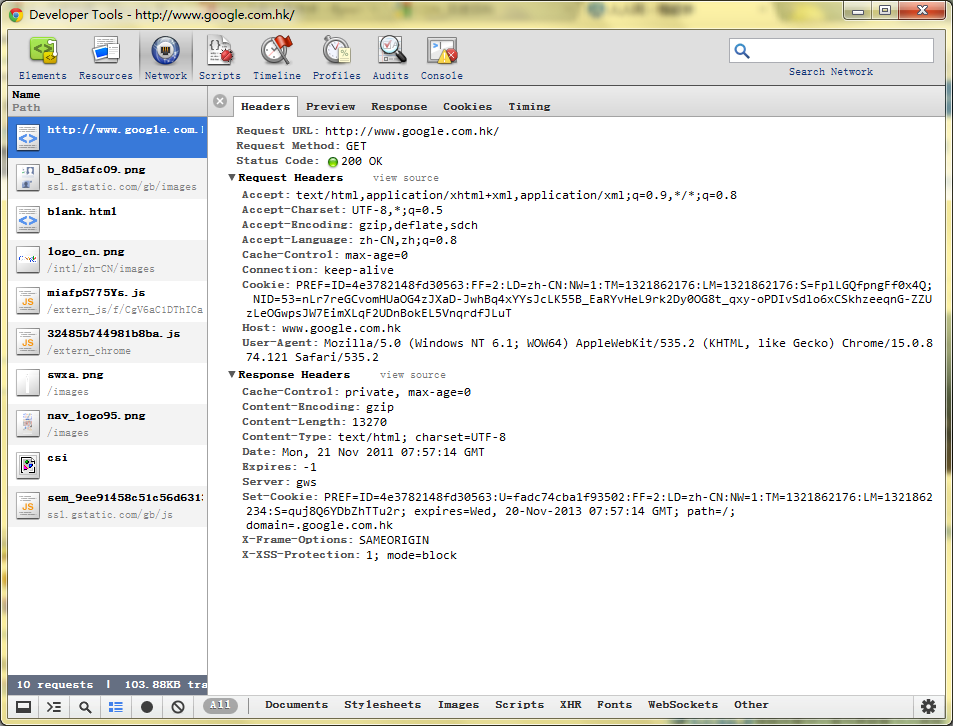
我们看到的,Request Header 里面的内容都是你访问的时候,浏览器提交的内容
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Charset:
UTF-8,*;q=0.5
Accept-Encoding:
gzip,deflate,sdch
Accept-Language:
zh-CN,zh;q=0.8
Cache-Control:
max-age=0
Connection:
keep-alive
Cookie:
PREF=ID=4e3782148fd30563:FF=2:LD=zh-CN:NW=1:TM=1321862176:LM=1321862176:S=FplLGQfpngFf0x4Q; NID=53=nLr7reGCvomHUaOG4zJXaD-JwhBq4xYYsJcLK55B_EaRYvHeL9rk2Dy0OG8t_qxy-oPDIvSdlo6xCSkhzeeqnG-ZZUzLeOGwpsJW7EimXLqF2UDnBokEL5VnqrdfJLuT
Host:
www.google.com.hk
User-Agent:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.121 Safari/535.2
其中,我们刚刚提到的,就是 Host 了,也就是主机名,也就是域名。但是除了这些,你看看,还有很多呢。
前面的 Accept 项目,就是你这个浏览器希望接受的内容,比如说我想看 html,xhtml 也可以之类的;我接受的字符编码,utf-8(这个就是 union code,中文有翻译为万国字符集的,简单说,就是基本包含了各个国家的字符编码,当然,有些浏览也会发送注入 GB2312 的字符集请求);接着,就是我们浏览器接受的内容编码了,我们知道 HTML 里面都是文本,所以通常是可以被压缩的,这样可以节省带宽,gzip 是其中的一种压缩格式;然后就是接受的语言,我这里就是中文简体,这个也是为什么你访问一些国际网站的时候跟国外的朋友看到的语言不一样的原因,其实你的浏览器已经悄悄地在这里告诉服务器你习惯的语言是中文了(这个跟你的系统设置有关,你改了语言这里也会发生改变,当然,浏览器本身也可以修改的属于浏览器的属性的)。
Cache 项目是描述你的浏览器怎么处理缓存的。大于 0 表示浏览器会在获得的这个内容后的这个数值对应的时间后删除这个缓存,以秒为单位,小于等于 0 的时候,缓存的删除是不确定的,浏览器请求的时候,会先和服务器进行商议,确定文件是否已经更新了,或者是缓存文件是否还存在,然后再确定是否传输文件。
Connect 属性是描述浏览器支持的链接类型,目前只有是否支持 keep-alive 这个项目,支持这个项目表示浏览器和服务器之间可以建立持久的通信,可以把数据传输在一次 TCP 过程中多次 HTTP 通信(在一定的时间内),不建立新的 TCP 请求。默认情况下,HTTP1.1 之后的都是打开的。
后面的 Cookie,是服务器给用户设置的身份信息,用于标识用户的,这个也就是为什么你在登录人人网一次之后(如果你选择下次记住登陆),在一段时间以内你都不需要再次登陆的原因。所以,Cookie 是一个私密的东西,不然的话,会泄漏你的秘密的~里面保存着的是你的身份信息,有时候,对于一些不注意信息安全的网站,你的密码甚至会被明文保存在那里!不过你就别想了,这里贴出来的,木有我的身份信息,我是通过隐私浏览选截图和例子给大家看的。
最后一个,就是用户的一些其他基本信息,成 User-Agent,主要是一些浏览器信息,已经系统信息,这里你明显注意到的是我用的是 Chrome15,64 位的 Windows7。有同学可能会质疑,为什么我前面写的是 Mozilla?这个不是火狐的公司么?其实这个是为了兼容性,因为 Mozilla/Netscape 最先发布网页浏览器的,对于一些古老的服务器,可能不认识你的浏览器,就不知道怎么给你提供网页的。那么我这里没写 Windows7 啊,为什么我说 windows7 呢?因为上面写了 NT6.1,就是 windows7 的内核版本号。对于 User-Agent,有时候还会包含一些插件信息的,比如你用 IE 的时候,就可能会把你.NET 的版本也会提交过去的。
最后,我们再看一张截图:

这里,我点击了另外一个页面,然后你们有没有注意到我们的 Request 有什么不一样呢?
嗯细心些童鞋应该发现了,多了一个
Referer: http://www.google.com.hk/
这个又是什么呢,如果你大胆去猜,应该猜到,这个就是你上次访问的页面。其实确切地说,这个是你对于这个新的 URL 的来源页,或者说,是这个新 URL 是被哪个页面引用的。这里可以说一下的是,referer 不是所有页面之间都可以传的,对于从 HTTPS 引用的页面,是不能向 HTTP 页面传送的。对于 Referer 的统计,也可以显示出用户在网站内部的浏览倾向,可以优化网站的结构和内容。
你提交的信息,有什么用?其实,这个答案是显然的,目的就是为了让服务器更好的为你提交针对性的服务,比如给你提供你喜欢的语言,为你的浏览器定制的网页(例如你用手机访问的,那个就是一个截然不同的 User-Agent 头部)。或者根据 Referer,检查网站被那个网站引用了,甚至通过分析来自搜索引擎的 referer 检查出自己网站来访者具体是为了什么问题而来的,或者是如果页面是个错误页,也可以根据 referer 判断我们的网站链接是不是有地方链接错了。或者是统计我们来访者的浏览器类型,做一些页面美工的修改,比如 IE6 浏览器非常恶心,我们是不是要支持那一部分用户,如果那一部分的用户群实在还很大,那么 Web 程序员只能很无奈地接受这个现实去做浏览器兼容了。诸如此类的。
但是,仅仅是这些而已么?绝对不是,如果细心的话,通过这些浏览信息,我们还可以挖掘出好多数据。别忘了,浏览者访问网站的时候,还有一个重要的属性,时间。联系上 IP 地址,我们甚至可以把浏览者的地理位置都确认出来,对于一些静态 IP 地址的地方,或者是 IP 地址分布很规律的地方,我们有时候能将 IP 对应的位置十分精确,比如到寝室号码。最搞笑的例子是当年在一些评论上看到的,就是清华大学某某楼第几层之类的地址了。其实,对于一些高校,这些地址真的可以对应得很细致,主要看怎么搜集这些地址。其实,对于时间,运用一些社会工程学的思想,我们也可以大致确定访问者的身份,比如学生的作息时间和其他人群就不一样,比如对于你熟悉的人,他的上网习惯时间都可以确定一些人的范围。然后集合对应的 User-Agent,判断他的操作系统,他的浏览器,对于那些小众的人群,就更容易确定了,比如说他是独一无二用 Opera 这类小众浏览器,用 64 位系统的。
这里补充说一句,其实上述的这些信息,对于每一个网页元素都会发送的,有时候为了统计方便,我们采用的是插入一个图片来获取这些统计信息的。
其实,对于一个网站的统计呢,上述的,还只是片面的,网站统计的时候,还有嵌入统计 JavaScript 的,比如 Google Analytic,通过 js,我们可以统计到更多的信息,比如你的浏览器是不是支持 Flash,支不支持 Java,或者是其他插件,再有就是你屏幕分辨率,现在浏览的窗口大小多少,等等,具体你可以去 Google Analytic 看看。有些情况下,这些还不够的,Js 甚至可以统计你点击了网页的那个位置(人人网就对于用户 ID 模某一个数的用户进行着这样的统计,主要是为了作为广告设置的参考),鼠标放在了哪个地方,在某个地方停留了多久(Google 这样统计过搜索结果页的这些信息),选中了什么词语(这个技术上是可行的,对于用户在想的东西,感兴趣的东西的统计)。其实,用户习惯就是一个很明显的特征,通过统计学的观点,是很容易体现出来的。
是不是觉得有点恐怖,你一次网页访问,怎么泄漏了那么多信息……其实,这些也已经是事实了,是 Web 工业化的一部分,如果你真的有必要去隐匿你的浏览,可以选择打开隐私浏览,然后选择一个代理服务器(最好是没有什么特征的服务器),甚至是用软件把你的 User-Agent 和其他有特征的头部信息去掉(有时候语言也是会泄漏你的身份的),把 JavaScript 禁用掉之类的(呃,不过别忘了,禁用 JavaScript 这个行为也让你显得很另类)。
这里有个隐私声明,我这个网站,作为一个对于我网站的统计需要,我也搜集浏览本网页的一些信息(当然,绝对不是说要把你们抓出来都是谁,主要是统计数据,不会对单一的数据点进行分析),其实,为的是让我写的东西更受大家欢迎。
最后,希望这篇文章对那些喜欢 Web 开发,或者即将做网站的同学有帮助,或者是普通的喜欢上网的同学有帮助吧。
如有疏漏,还请各位看官指正!